概述
无服务器计算,即通常所说的 Serverless,已经成为当前云计算领域的热门话题与趋势技术。无服务器计算是一种契合于当下云原生生态的开发、运行模式。无服务器并非不依赖服务器,而是对开发者而言服务器被抽象为更精确的算力单元。加州大学伯克利分校在论文 A Berkeley View on Serverless Computing 中提出的关于 Serverless 的观点——Serverless computing = FaaS + BaaS 被广泛接受,而 FaaS (函数即服务) 是 Serverless 的核心。
自 AWS Lambda 面世后,各大云计算巨头厂商纷纷投入 Serverless 战场,争相推出各自的 Serverless 或 FaaS 平台。另一方面,开发者不希望被特定厂商绑定的意愿也让开源的 Serverless 项目有了一席之地。如今 OpenFaaS(faas 仓库 20.3k)、Kubeless(6.7k)、Fission(6.4k)、OpenWhisk(5.4k)、Knative(serving 仓库 3.9k) 社区已经拥有大量的拥簇与开发者。
那么为什么 KubeSphere 社区要做一个自己的 FaaS 项目而不是直接集成现有的主流 Serverless 或 FaaS 框架?或者说现在的 Serverless 市场为什么还需要 OpenFunction ?
Serverless 新愿景
根据 CNCF 的云原生报告可以看出,Kubernetes 在容器编排技术领域拥有绝对的优势,甚至可以将 Kubernetes 作为云原生的代名词。云原生是目前备受瞩目的技术潮流,该领域的创新非常活跃,陆续涌现出了众多优秀的开源项目(比如 Serverless 领域的 KEDA、Knative 等),并且还将继续引领技术趋势。在 Kubernetes 宣布 1.20 版本将弃用 Docker、不再将其作为默认的容器运行时之后,尽管 Docker 仍然占据着容器运行时领域最大的份额,但对于云原生开发者来说,不得不开始着手顺应这方面的变化。
与此同时,人们生活方式的变化不断催生新的业务模式,5G、大数据、边缘计算、AI 推理、图数据库等服务应运而生。这些应用场景不但扩大了 Serverless 的潜在市场,结合云原生的技术潮流也孵化出很多新的技术,如 Dapr、WebAssembly 等。如何突破现有项目的局限引入更新更强力的技术,如何抹平运行时之间的差异降低应用的开发成本,逐渐成为了开发者的新烦恼。
OpenFunction 项目背景

OpenFunction开源项目链接:
https://github.com/OpenFunction/OpenFunction
OpenFunction 是 KubeSphere 社区发起的开源 FaaS 项目,目前的核心开发人员均来自 KubeSphere 团队。KubeSphere 社区一直陆续收到社区用户对 Serverless 或 FaaS 功能的需求,也注意到了社区开发者参与 Serverless 开发的兴趣:
KubeSphere 是否有计划集成 Knative ?我愿意参与开发!
KubeSphere 有 FaaS 方面的计划吗?是否可以集成 OpenFaaS ?
可否提供日志告警的功能?这个需求本质上是可自动伸缩的异步数据处理。
和云原生一样,Serverless 是个不容错失的赛道。仅仅集成现有的 Serverless 或 FaaS 项目还不足以体现 Serverless 这个领域的重要性,于是 KubeSphere 社区从 2020 年下半年开始对 Serverless 领域进行深度调研。经过一段时间的调研后,我们发现:
现有开源 FaaS 项目绝大多数启动较早,大部分都在 Knative 出现前就已经存在了;
Knative 是一个非常杰出的 Serverless 平台,但是 Knative Serving 仅仅能运行应用,不能运行函数,还不能称之为 FaaS 平台;
Knative Eventing 也是非常优秀的事件管理框架,但是设计有些过于复杂,用户用起来有一定门槛;
OpenFaaS 是比较流行的 FaaS 项目,但是技术栈有点老旧,依赖于 Prometheus 和 Alertmanager 进行 Autoscaling,在云原生领域并非最专业和敏捷的做法;
近年来云原生 Serverless 相关领域陆续涌现出了很多优秀的开源项目如 KEDA、 Dapr、 Cloud Native Buildpacks(CNB)、 Tekton、 Shipwright 等,为创建新一代开源 FaaS 平台打下了基础。
综上所述,我们调研的结论就是:现有开源 Serverless 或 FaaS 平台并不能满足构建现代云原生 FaaS 平台的要求,而云原生 Serverless 领域的最新进展却为构建新一代 FaaS 平台提供了可能。于是 KubeSphere 社区决定发起 OpenFunction 项目,其目标是构建新一代开源函数计算平台。
开源项目与社区发展
截至 2021 年 8 月, OpenFunction 陆续发布了 4 个版本,在最新的 v0.3.1 版里 builder 和 serving 部分已经趋于稳定,并且发布了 OpenFunction 自己的事件驱动框架 OpenFunction Events。KubeSphere 社区将持续在 OpenFunction 进行投入,最新路线图详见 OpenFunction Roadmap (https://github.com/OpenFunction/OpenFunction/blob/main/docs/roadmap.md)。
目前青云全象低代码平台已经采用 OpenFunction 实现灵活的低代码平台插件机制;也有来自 Nebula 的社区用户用 OpenFunction 实现了语音助手;有社区开发者为 OpenFunction 社区贡献了 NodeJS 版的 Function Framework 和 Builder。随着项目逐渐成熟,会有越来越多的社区用户使用 OpenFunction,我们也期待有更多的社区开发者参与进来。
OpenFunction FaaS 框架设计详解
OpenFunction 是一个开源的函数即服务(FaaS)框架,和大多数同类产品一样,旨在让用户专注于他们的业务逻辑,而不必担心底层运行环境和基础设施。如下图所示函数生命周期中几个重要的部分分别是: 函数框架(Functions framework)、函数构建 (Build)、函数服务 (Serving)和事件驱动框架 (Events Framework),下面我们将分别详细阐述这几个重要部分的设计及架构。
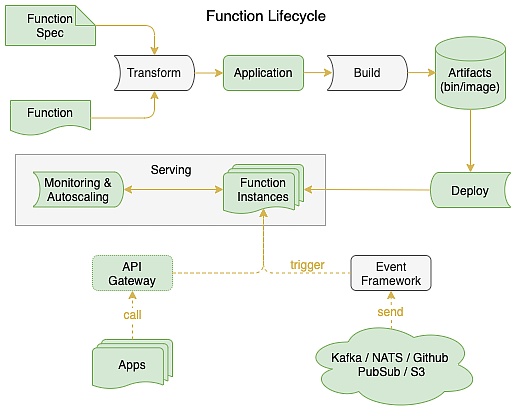
OpenFunction 函数生命周期示意图
函数框架(Functions framework)
在 FaaS 框架中,怎样将一段函数代码转换为可运行的应用是一个重要的环节。我们知道函数计算之所以降低了开发成本,正是因为函数框架(Functions framework)代替开发者完成了很多与业务无关的工作。不仅如此,函数框架还为开发者提供了应用运行环境中的上下文和语义明确的函数开发扩展库(可以理解为 SDK)。
这部分的设计并不复杂,实现的难点在于如何做到上述的语义明确和功能强大。
我们调研了几种主流的 FaaS 框架(平台),发现大部分的项目选择了封装函数入参的做法,其意图在于抽象输入数据的处理方式,即无论请求是什么格式,都可以使用框架提供的函数扩展库来获取数据。在这些成熟的案例中,我们发现封装入参的方式可以使函数在同一个框架内具有很高的灵活性和可扩展性。当函数的数据输入源变更后,函数本身不需要再做对应的入参适配,从而降低了使用者的开发成本。
从这个角度看,封装入参方式比不封装(或自定义)入参方式具备更大的潜力。接受了这个设定之后,我们再来看看函数框架的本质。函数框架本质上可以归纳为以下三个作用:
将用户提供的函数转换成可以运行的应用;
将用户函数封装为一个标准的访问地址,提供给输入端;
将输出端封装为一个标准的访问地址,提供给用户函数。
如果你了解过 Dapr,你就会发现后面两点和 Dapr 的工作原理几乎一致。Dapr 是一种分布式应用运行时,它以一种优雅的方式简化了开发者与中间件的交互。在 Kubernetes 中,Dapr 可以看作以 Sidecar 的方式实现了函数转换的功能。那么是否能用 Dapr 作为 FaaS(Serverless)平台中的 Functions framework?答案是肯定的。OpenFunction 正是基于 Dapr 提供了一套灵活的 functions framework 机制(其中包含了借鉴 Google functions-framework 处理 HTTP 函数的部分)实现了与各种复杂中间件的对接,并搭载两种运行时——以 Knative serving 为基础的同步函数运行时,和以 KEDA 结合 Dapr 为基础的异步函数运行时 OpenFunctionAsync,以期实现对实际生产中大部分应用场景的覆盖。
为了能让这个函数框架真正运作起来,往往还需要借助一些函数范围外的配置,用于定义函数和触发器、数据源、数据目标之间的关联关系。我们称之为函数上下文(OpenFunction Context),理论上它通常具备以下内容:
使用者通用元数据,如用户 ID、RequestID 等其他上下文信息;
事件源的定义,如名称、类型、服务地址、数据类型等;
触发器的定义,如名称、类型、触发规则、触发周期、执行方式等;
函数的定义,如名称、监听地址等;
提供自定义的 key-value 参数,如环境变量,以及用于适配不同的 Runtime 等。

OpenFunction 组件示意图
函数构建(Build)
我们通常会用 Build 来指代容器镜像的打包,但实际上将源代码打包成镜像只是构建工作中的一个步骤,开发者还有诸如拉取代码、代码预处理、镜像上传等工作需要完成。由此我们将 Build 拆分为两个主要的功能点,即制作容器镜像与创建构建流水线。在调研了 Cloud Native Buildpacks(CNB)、Tekton、Shipwright 等开源项目后,我们最终设计了 OpenFunction Builder CRD,为用户提供了一种可以自由选择 Build 方案的 Build 框架。
Docker 被 Kubernetes 放弃作为默认的容器运行时后,我们在 Kubernetes 中制作容器镜像还有多种选择比如 Kaniko、Buildah、BuildKit 以及 Cloud Native Buildpacks(CNB)。其中前三者均依赖 Dockerfile 去制作容器镜像,而 Cloud Native Buildpacks(CNB)是云原生领域最新涌现出来的新技术,它不依赖于 Dockerfile,而是能自动检测要 build 的代码,并生成符合 OCI 标准的容器镜像,已经被 Google Cloud、IBM Cloud、Heroku、Pivotal 等公司采用。
OpenFunction 选择 Cloud Native Buildpacks(CNB) 作为容器镜像制作的默认选择,陆续也会支持 Kaniko、Buildah、BuildKit 等方式。
Cloud Native Buildpacks(CNB) 的核心是 CNB Lifecycle,它负责将由应用源代码到镜像的构建步骤抽象出来,形成一套标准规范从而完成对整个过程的编排,并最终产出应用镜像。这样一来,开发者就可以将不同逻辑的最小构建单元 buildpack(可以理解为 Dockerfile 中的镜像分层) 按自身的需求组合到一起,生成一个构建器(builder),再交由 CNB 处理镜像的构建过程。
因为这是一套开源的标准,所以在 OpenFunction Builder 中开发者不但可以选择 OpenFunction 自身的构建器(builder)来构建镜像,还可以选择任何一种符合 CNB Lifecycle 的构建器,如 Google buildpacks、Paketo buildpacks 等,这意味着使用者可以构建任何语言、类型的应用。
Build 的另一个需求——构建流水线,就需要借助 Tekton 这样优秀的流水线工具作为支持。在最开始的版本中,OpenFunction 毫不犹豫地选择 Tekton 来拆分构建环节的工作,为之前所谈到的构建任务在 Tekton 中创建对应的 Task 及 Pipeline 等。
在对 Shipwright 的调研中我们发现 Shipwright 同样由 Tekton 驱动,并且 Shipwright 将 Tekton 的设计理念带入了镜像构建过程,形成了非常云原生的镜像构建框架,同时也支持使用 Kaniko、Buildah、BuildKit 以及 Cloud Native Buildpacks(CNB)构建镜像,并可以通过指定 BuildStrategy 和 ClusterBuildStrategy 在上述四种镜像构建方法之间进行切换。
于是我们在 v0.3.0 版本中将原有的 Tekton + Cloud Native Buildpacks 的构建方案切换成了 Shipwright。OpenFunction Builder 从设计上完美解决了如何在没有 Dockerfile 的情况下制作容器镜像的问题,并且具备了高度自由、云原生的构建器(构建方案)选择机制。无论是使用现成的 Dockerfile 还是仅用一段源代码,OpenFunction Builder 都可以将其构建为 Open Container Initiative(OCI)标准镜像并上传到指定的仓库中。
函数服务(Serving)
函数服务 (Serving)指的是如何运行函数 / 应用,以及赋予函数 / 应用基于事件驱动或流量驱动的自动伸缩的能力(Autoscaling)。我们根据这两个方面设计了负责运行函数 / 应用的 OpenFunction Serving CRD,并将函数分为同步函数和异步函数。同步函数是指客户端发出请求后,必须等到函数执行完成并获取函数运行结果后才返回;异步函数是指客户端触发函数后,无需等待函数运行结束即可返回。
在同步函数方面,Knative Serving 具备了非常出色的自动伸缩机制,OpenFunction 支持 Knative Serving 作为同步函数运行时,未来还将基于 KEDA http-add-on 开发 OpenFunctionSync 同步函数运行时。
在异步函数方面,我们结合 KEDA 和 Dapr 开发了 OpenFunctionAsync 异步函数运行时。Dapr 用于解耦函数对各种中间件的访问;KEDA 提供了 ScaledObject 和 ScaledJob 两种资源,用于根据实际事件源的监控指标自动进行工作负载副本数量的伸缩,它很好地弥补了 Knative Serving 在非 HTTP 驱动源场景中的不足。同时 KEDA 也在持续开发可以处理 HTTP 请求的 http-add-on 项目,这使得 OpenFunction 在后续的演进中具备了更多的选择,OpenFunction 未来将集成 KEDA http-Add-on 实现不依赖 Knative Serving 的 OpenFunctionSync 运行时。
我们将上面的工作集合起来,即使用 OpenFunction Serving CRD 来管理控制函数运行的整个生命周期。Serving CRD 包含了使用者对函数类型、输入、输出端的定义,以及函数实例自动伸缩的定义。OpenFunction Controller 会按照这些定义,生成相应的 Knative Service、Dapr 和 KEDA 组件,其中 Knative Service 负责同步函数的运行与自动伸缩;KEDA 会负责异步函数的自动伸缩,而 Dapr 会负责异步函数对接外部输入 / 输出。展开来讲, Dapr 会将外部的输入通过 OpenFunction Context 传递给 Functions framework,进而传递给函数;函数执行完成会通过调用 Functions framework 中相应的函数将输出通过 Dapr 输出到外部。
事件驱动框架 (Events Framework)
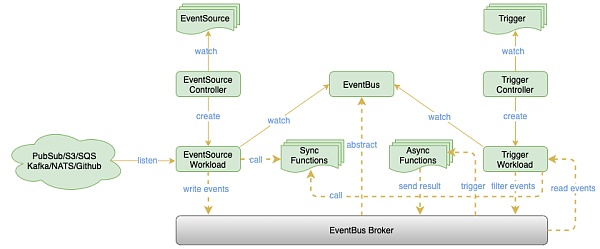
OpenFunction 事件框架示意图
除了核心的 FaaS 框架之外,OpenFunction 也设计了事件驱动框架以实现对异步函数的驱动。目前事件框架参考了 Argo Events 与 Knative Eventing 的部分设计,同时避免了引入类似 Knative Eventing 中过于复杂的设计;通过引入 Dapr 解耦了 EventBus 与底层具体 Message Broker 的绑定,进而利用 Dapr 的 binding 和 pubsub 分别对接事件源与 EventBus,以更优雅和可插拔的方式实现了类似 Argo Events 的架构,具备了对事件源的条件判断、对事件的流转控制等能力。
本质上来看,事件框架也是一个由事件驱动的工作负载,那么它本身可以是 Serverless 形式的工作负载吗?可以用 OpenFunction 的异步函数来驱动吗?其实 OpenFunction 社区已将该设计列入路线图中,目前也已实现部分组件的自驱动能力。
OpenFunction 的挑战
我们从一些关于 Serverless 的报告中可以看出,Serverless 服务有着可观的市场潜力,未来五年内也许就会达到千亿级的市场规模。然而对于 Serverless 技术本身来说,仍有很多待解决的问题,如冷启动、安全性、可观测性等等。
OpenFunction 在发展的过程中非常看中趋势中的技术,相信它们可以带来活力与变革能力(也许 Wasm 会成为 OpenFunction 的下一个服务运行时)。将成熟的与新生的技术掰开揉碎和在一起,再穿插进独立的设计与思考,或许就是 OpenFunction 解决上述问题的后发者优势,当然也是 OpenFunction 当下面临的挑战。
加入 OpenFunction 社区
期待感兴趣的开发者加入 OpenFunction 社区。可以提出任何你对 OpenFunction 的疑问、设计提案与合作提议。
作者:
方阗 | OpenFunction Maintainer
霍秉杰 | OpenFunction 发起人














